Goal
Build a practical ISL pipeline that moves from gesture/video input toward language-friendly outputs that can be consumed by downstream text/speech workflows.
Approach
The project is built around a dataset-first methodology:
- Curating and validating ISL gesture/video samples
- Preprocessing frames with OpenCV for cleaner model inputs
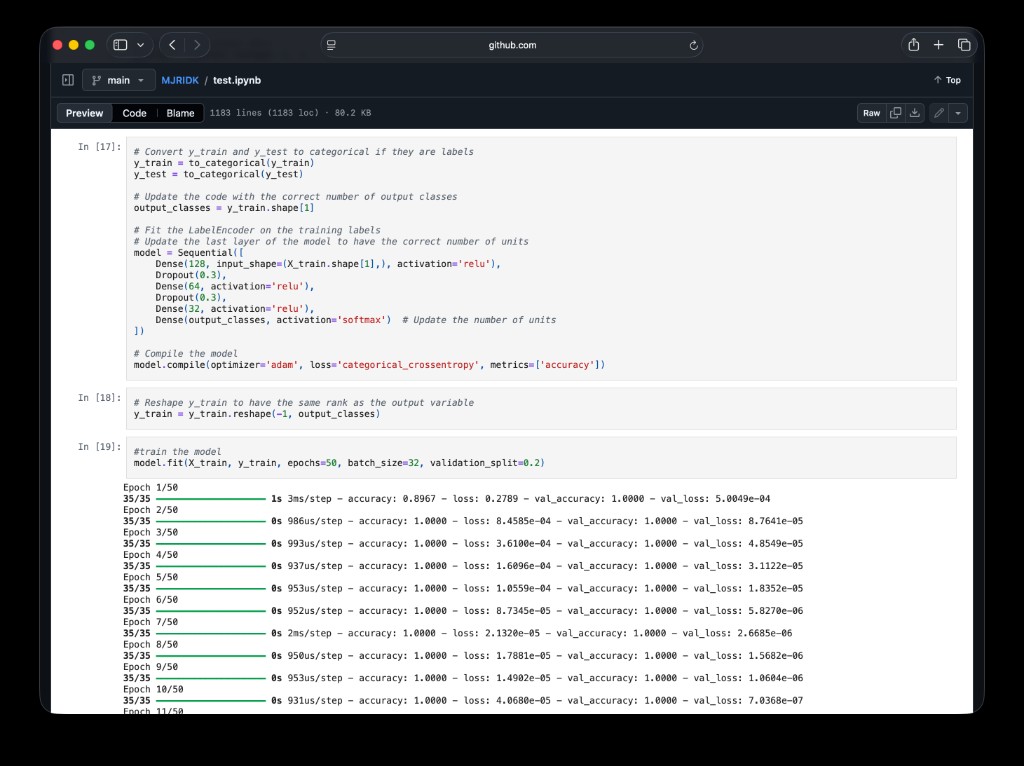
- Training/evaluating TensorFlow models for recognition quality
- Structuring outputs for NLP/post-processing stages
Dataset
The dataset is published on Kaggle and used as the core benchmark/source for iterative training and validation.
Current status
This work is in active progress with ongoing improvements in data quality, class consistency, and model robustness.